
��������Ⱥ�����O�ތW���C��ˮ�|�u�r��ģ�ͣ��h����
��������Ⱥ�����O�ތW���C��ˮ�|�u�r��ģ�ͣ��h����
���f�� ��÷*
���Ϻ����´�W��Ϣ���̌WԺ���Ϻ�201306��
ժҪ������ˮ�|���r�u�r���g����ǰ����ˮ�YԴ�����ͱ��o������Ҫ���x��ԓ���Ի���ˮ�|��������������Ⱥ�����ĘO�ތW���C��Particle Swarm Optimization-Extreme Learning Machine��PSO-ELM������㷨������ˮ�|�M��e�ж����ژO�ތW���C(ELM)����㷨���S�C�o��ݔ���ֵ��ꇺ��[����ƫ�ã���Ҫ�^����[���ӹ��c�����_������ľ���Ҫ���[���ӹ��c�^�����ڳ��F�^�M�ϬF�������㷨��Ӌ������ԓ����������Ⱥ�㷨(PSO)�����O�ތW���C��ݔ�˙�ֵ��ꇺ��[����ƫ�ã�Ӌ��ݔ����ֵ��ꇣ��Ԝp���[���ӹ��c��ͨ�^����PSO-ELM .ELM�@2�N�㷨�l�F,PSO-ELM�㷨���^�ٵ��[���ӹ��c�ɫ@�ø��ߵľ��ȣ������ˌ����ӱ����������������ģ�͵ĔM�����������Y��������PSO-ELM����ˮ�|e�ж�����һ���Ŀ����Ժ���Ч�ԡ�
�P�I�~������Ⱥ�������O�ތW���C��ˮ�|�u�r����ֵ���[����
�ЈD���̖��X824��TP18 doi��10.3969/j.issn��1003-6504.2016.05.026 ���¾�̖��1003-6504(2016)05-0135-05
�S����������lչ���˂�����ˮƽ�IJ�����ߣ�ˮ�YԴ�ı��o�ͺ������Â����Pע��ˮ������֮Դ�����a֮Ҫ�����B֮������ǰ��ˮ�YԴ��ȱ��ˮ��Ⱦ������Ȼ���Ƽs�҇���������ɳ��m�lչ����Ҫƿ�i���Ժ���������������Ҫ�ć����YԴ����������Ȼ���Bϵ�y����Ҫ�M�ɲ��֡������c�������lչ�����^�����Bƽ��ϢϢ���P�����М�ͨ���\������ˮ��������ƅ^�����B�h���Լ��ṩ���I�r�I�����ˮԴ�ȶ�N���ܡ�
�Թ��ԁ����غ����^�������Ϣ������Ͱlչ����Ҫ�^��������ˮ�|��rֱ��Ӱ푵��غ����^��������ˮ�|����ԓ�^��������İlչ����ˣ��˽�ˮ�|���ӵ���r�@���Ȟ���Ҫ��ͨ����ˮ�w�M���|���u�r���Д�ˮ�|��������Ч�ķ�������ˮ�h���Ķ����о�������ˮ�|�ķ���������ˮ�w�M����Ч��e�ж����O�ތW���C��һ�N�����O�ú����ұ��V�����õ��W�j�㷨��ԓ�㷨�S�C�o��ݔ����c�[�����g�ę�ֵ���[������Ԫ�g���ֵ����Ӗ���^���Пo���{����ֻ���O���[���ӹ��c�����Ϳɫ@��Ψһ����⡣���ǘO�ތW���C�㷨�S�C�a�����[���Ӆ�������ɾW�j���������^���������A�y���ȣ���Ҫ�����[���ӹ��c�������[���ӹ��c���^�������ӾW�j���s�ȣ����a���^�ȔM�ϵĆ��}��ᘌ�ELM��
�ڵĆ��}������������Ⱥ�㷨�����O�ތW���C�е��B�ә�ֵ���uֵ����������ˮ�|�u�r��PSO-ELMģ�ͣ�����������O�y�����M��ˮ�|e���ж���
1 �O�y�^�śr
���������̎�Ї��|���������L�����S�Ӄ�����֮�g��λ�ږ|��1120��1210������310��360��������e27�fkm2����������ͩ��ɽ����ţɽ���|�R�S�������Դ�eɽ���������ꡢͨ�P�\�Ӽ���̩�\���ϵ��c�L���ֽ磬�����S���ϵ̺�����ɽ�c�S���������������ښvʷ���S�����Z���˺����F���ӷ֞黴��ˮϵ��������ˮϵ���U�S�����Ϟ黴��ˮϵ���Ա���������ˮϵ����ɺ����黴�����Σ�ˮ����·��й������ͨ�^�����l�������ӣ��������������]���������I���L�����ɞ��˽�ˮ��������ȫ�L�s1 000 km��������e187 000 km2����һ·�ں�ɺ��|�����������l�����K����ȿ����ڱ�������S��������·�ں�ɺ��|�����������l��������ӱ����B�Ƹ��У����R���ע�뺣�ݞ�������֧�����࣬������e����1�fkm2��һ��֧����4�l������2 000 km2��һ��֧����16�l������1 000 km2��һ��֧����21�l����������������������ϡ����ա����K��ɽ�|5ʡ35���أ��У���189���h���У�������������1.2x105 km2���أ��غ�߀�н�6.7x103 km2��Ϳ���Y�_������������V�a�YԴ�S������ú̿�YԴ��࣬����̽����ú̿������700���|t��ú̿�a���sռȫ����1/8��һ���µĴ��͵V�������d���������������Ї������lչ���e���p�ء�Ȼ���L���ԁ����S����
�ؽ����ĸ��ٰlչ���@һ�����ˮ���B�h��Ҳ��ܴ��Ɖģ�ˮ�|��Ⱦ�����ą^��r�г��F�����r�O�y������ˮ�|�������@һ�^��ĭh������������Ҫ���x��
�������Խ��K�������Ӵ��O�y���桢�����ܿ������l�O�y����Ͱ��ո�ꖏ����O�y����팦����ˮ�|�M���u�r�����K�������Ӵ��O�y�����ƽ��ˮ�|�ȼ�������p����Ⱦ�������ܿ������l�O�y����ƽ��ˮ�|�ȼ���V�������Ⱦ�����ո�ꖏ����O�y����ƽ��ˮ�|�ȼ���V�������Ⱦ�����ڻ���ˮ�|e���u�r�A�y������Ҫ�ĬF�����x�;o���ԡ����r���u�r���A�����܉���Ч�������������P���T���r�����A���ͱ��o����������ˮ�|�Mһ��������
2 ������Դ������Ⱥ�����ĘO�ތW���C�㷨
2.1 ������Դ
�҇���ȫ�������ȵ���Ҫˮϵ������ˮ�|�ԄӱO�yվ������Ŀǰ����145�����c����ˮ�|�ԄӱO�yվ���əz�y����ָ�˹���8헡������x�û�������O�y���漴���K�������Ӵ��O�y���桢���ո�ꖏ����O�y����ͺ����ܿ������l�O�y���档3���O�y����ֲ����1��ʾ��

���Ęӱ������������A���͇��h�����o���������İl����“ȫ����Ҫ�������c����ˮ�|�ԄӱO�y�܈�”���xȡ��A��(pH)���ܽ���(DO)������(NH3-N)�������������i���}ָ�������ָ�ˡ��������ر�ˮ�h���|���˜ʡ�( GB 3838-2002)���о��^�ȸ���Ҫ�����ˮ�w�|��չ�_�u�r�о����@Щ���������Ա���ˮ�w��Ⱦ�̶ȣ������@Щ������ˮ�|e�M���ж��ǜʴ_�ͿƌW�ġ��ɼ���2013����2014��90�ܵĻ���ˮ�|������Ӗ���ӱ���������2015���ϰ����ǰ13�����yԇ�ӱ�������������3������M��ˮ�|e�ж���3��O�y�����Ӗ���ӱ������͜yԇ�ӱ�����ȡ�ԡ�ȫ����Ҫ�������c����ˮ�|�O�y�܈�
2.2 ��������Ⱥ�����ĘO�ތW���C�㷨
�O�ތW���C��һ�Nᘌ�SLFN�����㷨���O�ތW���C��ݔ�˙�ֵ���w���[����ƫ���ֵb���S�C�o���ģ�ֻ��Ҫ�O�þW�j���[���ӹ��c�������ܮa��Ψһ����⣬���ЌW���ٶȿ��ҷ������ܺõă��c����ͨ�^��⾀�Է��̽M����С���˽�@��ݔ����ֵ��
�mȻ�O�ތW���C�ڴ���r�¿��ԫ@�����õ����ܣ������B�ә�ֵw��ƫ���ֵb���[���ӹ��c���������O�ތW���C�ľ��ȶ����ںܴ�Ӱ푡�ݔ����ֵ�����ݔ�˙�ֵ��ꇺ��[����ƫ��Ӌ��õ������ܕ�����ݔ���ֵ��ꇺ��[����ƫ��������r���������[���ӹ��c�ǟoЧ�ġ������һЩ���H�����У��O�ތW���C��Ҫ�������[���ӹ��c�����_���A�ڵ�Ч�������[���ӹ��c�^�������ӾW�j���s�ȣ����a���^�M�ϬF������ɘO�ތW���C�ķ����������͡�
����Ⱥ�㷨��һ�NȺ�w���ܵă����㷨����һ

��ÿһ�εĵ����^���У�����ͨ�^���w�Oֵ��ȫ�֘Oֵ�����������ٶȺ�λ���_��Ҫ�M��ėl����Y�����������¹�ʽ���£�
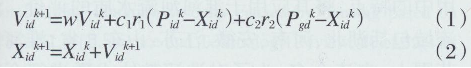
����������Ⱥ�㷨�����O�ތW���C�е��B�ә�ֵ���ֵ����������ˮ�|�u�r��PSO-ELMģ�͡����O�ތW���C��ݔ�˙�ֵ���ֵ��������Ⱥ�㷨��

���ڷNȺ�е�ÿ�����w����ݔ�˙�ֵ��ꇺ��[����ƫ����ØO�ތW���C�㷨Ӌ��ݔ����ֵ��ꇡ���ÿ�����ӵľ������`����������Ⱥ�����㷨���m���ȣ��ɘO�ތW���C��Ӗ���ӱ�Ӌ������ӵľ������`�����Ⱥ�����O�ތW���C�㷨�ľ��w���E��
(1)�o���W���ӱ����W���ӱ�����ݔ������������ݔ��������
(2)����PSO-ELM�W�j�ؓ�Y���������_��ݔ��ӡ��[���ӡ�ݔ���ӵ���Ԫ�������x�����
(3)�a���NȺ��ԓ�NȺ�ɘO�ތW���C��ݔ�˙�ֵ���ֵ�M�ɣ���ʼ������λ�ú������ٶȣ�������ֵ���ֵ�ķ����O�������ٶȺ�λ�õČ���������
(4)�x���m�ϵą�������Ҫ���������Δ�T=500���NȺҎģM=20���T�ԙ�ֵw=1���W������C1=C2=
2�����ӾS��D��
(5)�_���ԘO�ތW���CӖ�����ľ������`�������m����ֵ������Ӌ���ÿ�����ӵ��m����ֵ�����ÿ�����ӵĂ��w�Oֵ��ȫ�֘Oֵ��
(6)ͨ�^���^������������ӵ��ٶȺ�λ�ã�
(7)�Д��Ƿ��_���������Δ�������С�`����_�����tֹͣ�������˕r��Ⱥ�w�Oֵ���ǽ��^PSO������ELMݔ�˙�ֵ���[�ӹ��c�ֵ�����]�_�����D�����E5���^�m�������乤�����̈D��D1��ʾ��
3 �Y���c����
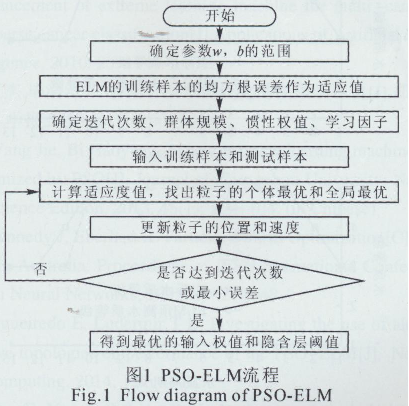
���������@ȡ�Ęӱ�������������Ⱥ�����ĘO�ތW���C�㷨�M��ˮ�|�u�rģ�ͽ�ģ��ʹ��2013����2014���90��ˮ�|��ģ���M��Ӗ����Ȼ����2015���13��ˮ�|��ģ���M�Мyԇ��Ӗ���õ�����Ⱥ�����ĘO�ތW���C�u�rģ�͌�����3�O�y�����M��ˮ�|e�ж�����Y����D2��3��4��ʾ��
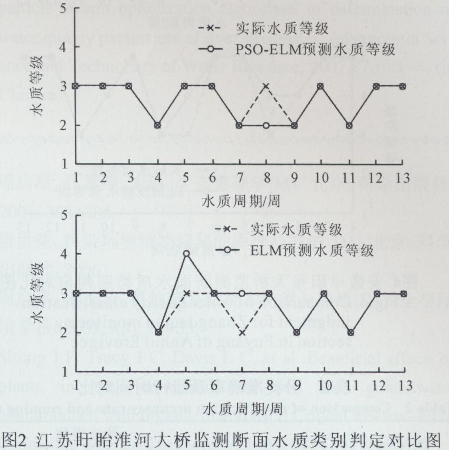
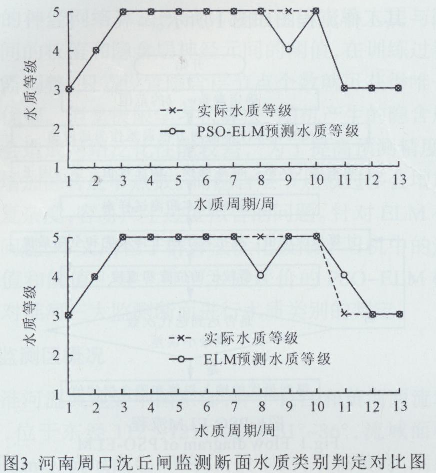
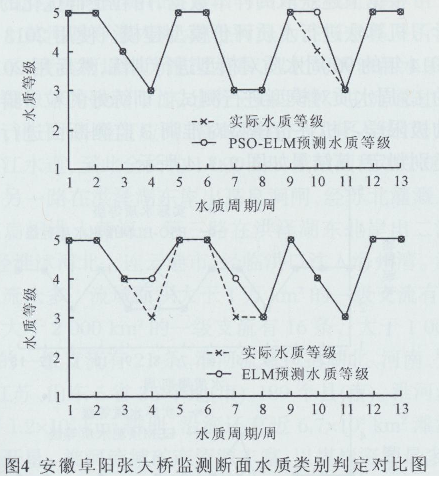
�C�ψD2���D3���D4�ͱ�2���ȿ��Կ������ڽ��K�����O�y���桢�����ܿڱO�y����Ͱ��ո�ꖱO�y������PSO-ELM���ģ���M��ˮ�|e�ж����_�ʶ��_��92.31% (12/13����ʾ��3��O�y�����13��ˮ�|�yԇ�У���12�ܵ�ˮ�|�ȼ��u�r���_)���քe����8�ܡ���9�ܺ͵�10�u�r�e�`�⣬�������ˮ�|�u�r��ȫ���_������ELM���ģ���M��ˮ�|e�ж����_�ʾ���84.66%(11/13����ʾ��3��O�y�����13��ˮ�|�yԇ�У���11�ܵ�ˮ�|�ȼ��u�r���_)����˿��Եó�������Ⱥ�����^��ĘO�ތW���C��ˮ�|e�ж����_�����@���ڛ]�Ѓ����ĘO�ތW���C��ELM���ģ���\�Еr�g������2s���mȻELM���ģ�͵��\�Еr�g��PSQ-ELM���ģ���̣����ڷ�ʴ_���υs�Ԟ��dɫ��PSO-ELM���ģ�͵ķ�ʴ_���^�ߣ��w�F���^���ķ�������Ϳ��ɔ_�����������^�õķ���������ELM���ģ�͵ķ�ʴ_�ʴ�֮����Ҋ����PSO-ELM���ģ���M�л���ˮ�|�u�r�����^�ߵĜʴ_�Ժͺ����ԡ�
4 �YՓ
������������Ⱥ�����O�ތW���Cģ���ڷ�����е����c�����䑪���ڻ��Ӻ���ˮ�|���u�r����������������������ϡ����ա����K��ɽ�|5ʡ������������֧�����࣬���ˌ��������wˮ�|�M�к������u�r�����xȡ���K�����������ܿڡ����ո��3��O�y���档ͨ�^ʹ�ù��_����������3��O�y�����M��ˮ�|e�ж������Y��������ԓģ������Ч�،������������wˮ�|�����˺������u�r����Ӗ���ӱ���r��ͬ�ėl���£�������Ⱥ�����O�ތW���C�c�O�ތW���C�ɷN���ģ�͵��A�y��Y���M�Ќ��Ⱥ�l�F��ʹ������Ⱥ�����O�ތW���Cģ�͵ķ�Y��Ҫ���ژO�ތW���C�㷨������Ⱥ�����O�ތW���Cģ��������㷨�ķ����ԣ�����Ч����Ӗ��“�^�W��”�Ć��}��ʹ��ģ��Ӗ�����Ⱥͷ��������@����ߣ����ҽ������A�y���Ȍ�Ӗ���ӱ������[���ӹ��c��׃�������жȡ���ˣ�����Ⱥ�����ĘO�ތW���C�㷨��һ�N����ˮ�|�u�r�о�����Ч�·���������������u�r�c���������һ�����ƏV�rֵ��