
����ͨ(li��n)��(sh��)��(j��)�����H�P(gu��n)ϵ�W(w��ng)�j(lu��)��(g��u)���c�ھW(w��ng)�j(lu��)��
���P(gu��n)朽ӣ� �Ї���ȫ�W(w��ng) �Ї��|(zh��)���W(w��ng) �Ї�Փ�ľW(w��ng) �Ї��YӍ�W(w��ng)
����ͨ(li��n)��(sh��)��(j��)�����H�P(gu��n)ϵ�W(w��ng)�j(lu��)��(g��u)���c�ھW(w��ng)�j(lu��)��
�����������������㣬�����c
(�����������о�����Ϣ�W(w��ng)�j(lu��)��ȫ���������c����ң��Ϻ�201400)
ժҪ���W(w��ng)�j(lu��)ͨӍ��Ȼ�ɞ�����Ϣ�r����ߴ����ԵĮa(ch��n)��Ñ�֮�g���罻�P(gu��n)ϵҲ׃��Խ��Խ������Խ��Խ��Ҫ������ͨ�^ģ�Mͨ(li��n)��(sh��)��(j��)���������ķ��~����Ȼ�Z��̎���ȼ��g(sh��)��(g��u)����ӳ���H�P(gu��n)ϵ��ͨ(li��n)���ѾW(w��ng)�j(lu��)�����O(sh��)Ӌ��һ�N�m���ں��ѾW(w��ng)�j(lu��)���H�P(gu��n)ϵ�A�y�Ķ����㷨��ԓ�㷨�������ÌӴξ��ԭʼ��(sh��)��(j��)�M�о���Y(ji��)���˹����A���_����KĂ���(sh��)���Ķ���Ч����ͨ(li��n)�ֽM��Ϣ�Ķ��x�~����ɵ�e��(sh��)�^��Ć��}��Ȼ����ͨ(li��n)����ӛ䛵���Ϣ����A(ch��)�O(sh��)Ӌ������������������С�ӱ��£����Џ��s�Q��߅�罨ģ������֧�������C( Support VectorMachine��SVM)�M��Ӗ�����õ��m�������H�P(gu��n)ϵ�A�y�ķ��ģ�ͣ�������δ֪���H�P(gu��n)ϵ���A�y��
�P(gu��n)�I�~��ͨ(li��n)��־�����H�W(w��ng)�j(lu��)���Ñ��������P(gu��n)ϵ�A�y��SVM
�ЈD���̖��TP309 ���¾�̖��1671-1122( 2016) 06-0068-060�о��F(xi��n)��
������W���y(t��ng)Ӌ�W�͈DՓ�I(l��ng)���У�ᘌ��������W(w��ng)�j(lu��)���о��Ɂ��Ѿá���������ھW(w��ng)�j(lu��)�Y(ji��)��(g��u)������О�ȸ�����Ҳȡ���˱���Ŀ��гɹ������W�����c���罻�W(w��ng)�j(lu��)��(ji��)�c��Ӱ����M���������о���
�n�����ͨ�^�����罻�W(w��ng)�j(lu��)��朽ӽY(ji��)��(g��u)���O(sh��)Ӌ��һ�N������ه�P(gu��n)ϵ��֧�νY(ji��)��(g��u)ģ�ͼ�Ӌ�㷽�������ڴ_���罻�W(w��ng)�j(lu��)���ض���(ji��)�c��Ӱ�����Դ�����⣬���Ŗ|���ˏľW(w��ng)�j(lu��)�ؓ䡢�Ñ��О�ͽ�����Ϣ�Ȏׂ����濂�Y(ji��)��Ӱ��������Ľ�ģ�Ͷ������������o���ˌ��罻�W(w��ng)�j(lu��)���Ñ��Ěvʷ�О���־�����ӱ������b�����Ȼ��Ӌ��˼�댦�Ñ��gӰ����W�����}��ģ�������ھ����ֵģ�͵Ŀ���£����һ�NӰ���������(qu��n)�ص�Ӌ�㷽������С�����������_һ�N�·f�Ļ����S��(ji��)�c�x����ԵĴ�D��Ҫ��(ji��)�c�н�Ƚ���Ӌ�㷽����ԭ��ϵ�y(t��ng)����ͨ�^ģ�M��(sh��)��(j��)���挍��(sh��)��(j��)������һ���B�m(x��)�����µ��挍�罻�W(w��ng)�j(lu��)��(sh��)��(j��)�����M������C���ڙC���W�������đ�(y��ng)�÷��棬�ܾ��µ���ʹ�Ø���ؐ�~˹NaiveBayes��߉�ؚwlogisticsRregerssion�ȷ���������Ñ���ԡ��罻�P(gu��n)ϵ������(n��i)����C�����������o�������Ñ��D(zhu��n)�l(f��)�О��M���A�y���~�ȵ���ᘌ��R�e�罻�W(w��ng)�j(lu��)�Ñ��r���ڵ�ģʽ��һ���}������˻��ڷ։K�Ͷ����D���Ñ��R�e�㷨������܊������Փ�ĺ����W(w��ng)�j(lu��)����A(ch��)������(j��)�W���l(f��)��Փ�ĕrͨ���c������ͬ�����ĬF(xi��n)������܉�ӳ����һ�W�������P(gu��n)ϵ����������������������ģ�͵Č���һ�W���P(gu��n)ϵ�R�e�㷨����������ˏĻ����О����������ڃ�(n��i)�ݡ����ڈD( Graph)���o�O(ji��n)���W���Ă����挦������罻�W(w��ng)�j(lu��)�Ю�����̖�z�y�����M��ϵ�y(t��ng)�ԵĚw�{���Y(ji��)������δ��������̖�z�y���о�څ���M����չ����
1����ͨ(li��n)��(sh��)��(j��)�����H�P(gu��n)ϵ�W(w��ng)�j(lu��)��(g��u)��
1.1���w��ȡ
ʹ���ֵ��(q��)�ӷ�ʽ���ڽY(ji��)��(g��u)����ͨ(li��n)��(sh��)��(j��)�M�Ќ��w��ȡ�����w��ȡ��ԭ�t�nj��w��������Ψһ�ԣ����܉�Ψһ���F(xi��n)ԓ���w�����������w���������ǹ����ģ�Ҫ���������w�����P(gu��n)(li��n)�P(gu��n)ϵ�����w����Ҫ�����ڌ��w�����������a�䌍�w���������P(gu��n)(li��n)�P(gu��n)ϵ��ͨ�^�S�C���ɷ�ʽ��ģ�M��—�f�l��(sh��)��(j��)���������ҏ�ͨ(li��n)��(sh��)��(j��)���������c���l(f��)���x�����Ҫ�Č��w��
1)�Ñ����R��ģ�M��(sh��)��(j��)���S�C�a(ch��n)�����ķN���Ԯ������w���ֶΣ������֙C̖�a���]�䣬QQ�~̖�Լ���ģ�M��(sh��)��(j��)���ɵ��Ñ�Ψһ���R�������Ñ������w��Ҫ�����~̖��͵Č��ԣ�����̖��e���ԅ^(q��)�֡�ͬ�r�Ñ����R������һЩ�ɴ�(li��n)���P(gu��n)(li��n)���w�����磬�O(sh��)��̖���C��̖���ϾW(w��ng)�~̖���Ñ�����IP��ַ��
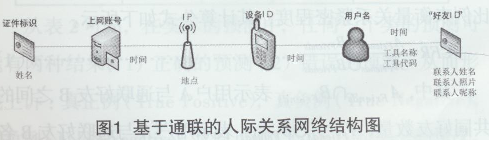
2)���ј��R��ͨ(li��n)��(sh��)��(j��)���P(gu��n)ϵ���ѵ��]����Ϣ�Á�Ψһ���Rԓ���ѣ���������ȱʧ��r���R���w��Ҫ�a��ӛ�ID�����e�ɱ���ͬһ��(ji��)�c�������ڲ��ò�ͬ���R����ҕ�鲻ͬ�Ĺ�(ji��)�c���M�����C���H�P(gu��n)ϵ�W(w��ng)�j(lu��)�������ԣ���ȡ�Y(ji��)�����1��ʾ��

1.2���w�P(gu��n)ϵ��ȡ
���w�g�������o�ܵ��B���P(gu��n)ϵ�����磬�C��̖�a���ϾW(w��ng)�~̖�ɂ����w�g��Ҏ(gu��)���r�g�^(q��)�g��(n��i)��һ��һ���P(gu��n)ϵ��һ���C��ֻ̖�ܓ���Ψһһ���ϾW(w��ng)�~̖��һ���ϾW(w��ng)�~ֻ̖��������һ�������C̖��ͬ�r�ϾW(w��ng)�~̖���Դ�(li��n)�����~̖���е�IP��ͨ�^IP�����P(gu��n)(li��n)����IP����ʹ�õ��O(sh��)����r���Mһ����Ɍ����Ñ�̓�M���ݵĴ�(li��n)��ͨ�^�Ñ����@һ�����w�Ϳ��Ժ����Ę�(g��u)���Ñ��ĺ��ѾW(w��ng)�j(lu��)���Ķ��Uչ������Ñ��P(gu��n)ϵ�W(w��ng)�����ڌ��w�g�P(gu��n)ϵ��������Ҫ�ĕr�g�S�ȳ��l(f��)�����c���ѵČ��w�P(gu��n)ϵ߀����ͨ�^��ͬ���ς������M�з�����w��ȡ�Y(ji��)����D1��ʾ��
2����֧�������C�����H�P(gu��n)ϵ�A�y
�������ķ��~����Ȼ�Z��̎�����ı��ھ��g(sh��)����ͨ(li��n)��(sh��)��(j��)���܉�ӳ���c��֮�g���H�P(gu��n)ϵ���ı���(sh��)��(j��)�M�з���̎����������ȡ�T��ͬ�¡����ѡ�ͬ�W�����˵ȷ�ӳ���H�P(gu��n)ϵ���ض��~�Z��Ȼ���Դ���~�Z���鹝(ji��)�c�g߅�Č��ԁ혋(g��u)�����H�P(gu��n)ϵ�W(w��ng)�j(lu��)�������ͨ(li��n)ӛ䛡����Ł���ӛ䛵���Ϣ����A(ch��)�O(sh��)Ӌ������������������С�ӱ��¾��Џ��s�Q��߅�罨ģ������֧�������C( Suppport Vector Machine,SVM)�M��Ӗ���õ��m�������H�P(gu��n)ϵ�A�y�ķ��ģ�ͣ�������δ֪�P(gu��n)ϵ���A�y��
2.1���H�P(gu��n)ϵ�A�yģ�͵Ľ���
�����A�y���H�W(w��ng)�j(lu��)�еăɂ���Ȼ���Ƿ�����H�١����ѻ������P(gu��n)ϵ������ͨ�^�����F(xi��n)�о����ض����H�P(gu��n)ϵ���Ñ�֮�g�͟o�P(gu��n)ϵ�Ñ�֮�g���О���������O(sh��)Ӌ�N�������÷�������Č����������������M����(g��u)��Ӗ���ӱ��������Ƿ�����P(gu��n)ϵ�������P(gu��n)ϵe���ж��D(zhu��n)�Q�ɔ�(sh��)��(j��)�ھ��еķ���}��
2.1.1�����x��
1)��ͬ���є�(sh��)��ռ���ѿ���(sh��)�ı���CFR
KOSSINETS����ͨ�^�о���У��W��֮�g�������P(gu��n)ϵ�W(w��ng)�j(lu��)���l(f��)�F(xi��n)����֮�g�Ĺ�ͬ���˔�(sh��)Ŀ�ںܴ�̶��ϛQ������֮�g�Ƿ����(li��n)ϵ������ͬ���˔�(sh��)Խ���t����Ҳ�����˵Ŀ����Ծ�Խ���@Ȼ�ɂ���Ȼ��֮�g�Ĺ�ͬ���є�(sh��)��Խ�࣬����֮�g���ں����P(gu��n)ϵ�Ŀ�����Խ���෴�tԽС��
���džμ��Թ�ͬ���є�(sh��)���������ɂ���Ȼ��֮�g�P(gu��n)ϵ�ľo�̶ܳȴ������@��ȱ�ݡ����O(sh��)�Ñ�A�c�Ñ�B֮�g�Ĺ�ͬ���є�(sh��)����5�����Ñ�A�ĺ��ѿ���(sh��)��30���Ñ�B�ĺ��ѿ���(sh��)��100��ô�Ñ�A�����c��ʣ�������25�����Ѹ���o�ܵĿ����ԣ�ͬ���Ñ�Bͬ�Ӵ����c��ʣ�������5�������P(gu��n)ϵ����o�ܵĿ����ԣ����Ǻ��ѿ���(sh��)������Ñ�A��������Ը����˱���˷N�����Ե�Ӱ푣����ú��ѿ���(sh��)�����(sh��)�����ù�ͬ���є�(sh��)��ռ���Ժ��ѿ���(sh��)�ı����������P(gu��n)ϵ�o�̶ܳȣ���Ӌ�㹫ʽ������ʾ��

2)ƽ��ͨ(li��n)�Δ�(sh��)AR
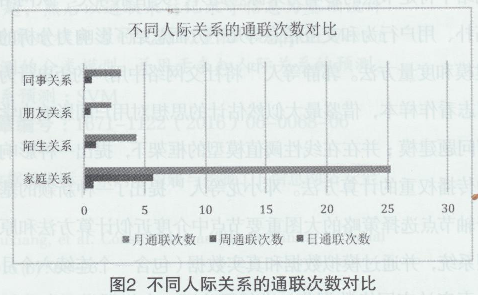
AR��ָ���^�y��(sh��)��(j��)������(n��i)���ɂ��Ñ�֮�gͨ(li��n)�Δ�(sh��)���քe�y(t��ng)Ӌ���F(xi��n)�Д�(sh��)��(j��)������֮�g����ƽ��ͨ(li��n)�Δ�(sh��)����ƽ��ͨ(li��n)�Δ�(sh��)����ƽ��ͨ(li��n)�Δ�(sh��)���ڲ�ͬ���H�P(gu��n)ϵ֮�g�M�Ќ��ȣ�ȡ�����з���������ָ�ˁ�����ƽ��ͨ(li��n)�Δ�(sh��)����D2��ʾ����Ӌ�㹫ʽ������ʾ��

3)ƽ��ͨ(li��n)�r�LATR
�H�H���Ñ�֮�gƽ��ͨ(li��n)�Δ�(sh��)�������ԅ^(q��)���Ñ����P(gu��n)ϵ�o�̶ܳȡ����磬�Ñ�A�c�Ñ�B֮�g��ͨ(li��n)�Δ�(sh��)�c�Ñ�B�c�Ñ�C֮�g��ͨ(li��n)�Δ�(sh��)��ͬ�����Ñ�B�c�Ñ�C֮�g��ͨ(li��n)�r�L���L���@Ȼ���ߵ��P(gu��n)ϵ����o�ܡ������б�Ҫ����ƽ��ͨ(li��n)�r�L������������ԓ����ָ���^�y��(sh��)��(j��)������(n��i)���ɂ��Ñ�֮�gͨ(li��n)��ƽ���r�L����λ���룬��D3��ʾ����Ӌ�㹫ʽ������ʾ��


4)ƽ����Ϣ�����Δ�(sh��)AM
AM��ָ���^�y��(sh��)��(j��)������(n��i)���ɂ��Ñ�֮�g�l(f��)����Ϣ�ĴΔ�(sh��)��ͬ�ӷքe�y(t��ng)Ӌ���F(xi��n)�Д�(sh��)��(j��)������֮�g��Ϣ��������ƽ������ƽ������ƽ���Δ�(sh��)���ڲ�ͬ���H�P(gu��n)ϵ֮�g�M�Ќ��ȣ�ȡ�����з��������ĵ�ָ�ˁ�����ƽ����Ϣ�����Δ�(sh��)����Ӌ�㹫ʽ������ʾ��

�����O(sh��)Ӌ��4������������H�P(gu��n)ϵ���h����Ҏ(gu��)����׃���������H�P(gu��n)ϵԽ�o����ͨ(li��n)�Δ�(sh��)��ͨ(li��n)�r�L��(sh��)ֵԽ�����H�P(gu��n)ϵԽ���h��ͨ(li��n)�Δ�(sh��)��ͨ(li��n)�r�L��(sh��)ֵԽС������“��ͥ�P(gu��n)ϵ”֮�gͨ(li��n)�r�L��ͨ(li��n)�Δ�(sh��)���h�h������������P(gu��n)ϵ���Ҳ�ͬ�P(gu��n)ϵ֮�g������һ���IJ����Ҋ�����V4�������������һ���̶��υ^(q��)�ֲ�ͬ�����H�P(gu��n)ϵ���Ķ��������H�P(gu��n)ϵ�A�yģ�͵�Ӗ����
2.1.2Ӗ���ӱ��Ę�(g��u)��
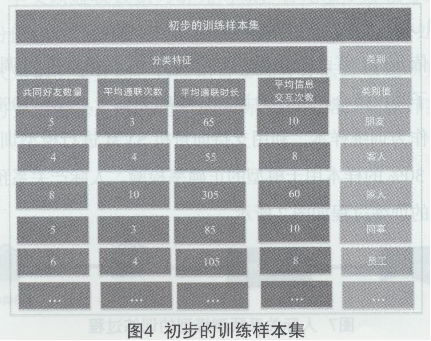
�@ȡ�Ƀ���Ȼ��֮�g��ͨ(li��n)ӛ䛔�(sh��)��(j��)����Ϣ��Ϣ��������Ϣ��(sh��)��(j��)���քe����(j��)2 .1.1��(ji��)�_����Ӌ�㷽���M��Ӌ��õ���ͬ���є�(sh��)����ƽ��ͨ(li��n)�Δ�(sh��)��ƽ��ͨ(li��n)�r�L��ƽ����Ϣ�����Δ�(sh��)4������������õ�������Ӗ���ӱ�����(sh��)��(j��)�ΑB(t��i)��D4��ʾ��
����ͨ(li��n)��־�����P(gu��n)ϵ������һ�¡����磬���ѡ������@�����ȫ���Ժϲ���ͬһ�̎��������������“����”��ϲ�ǰ��Q��ԭʼ��ϲ���Ĵ�Q����K����@�ӱ�����F(xi��n)���������e��������Ӗ���ӱ����|(zh��)����
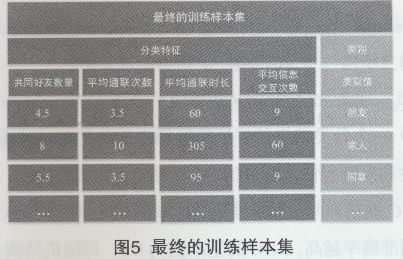
���Č�����������Ӗ���ӱ��\�ÌӴξ���M��ĺϲ���̎��ԭ�t���£�1�����ÌӴξ��e�ɿ����c���˹����Aĺϲ����Mһ�������|(zh��)����2���ϲ������K��ӱ�������ֵ�ɺϲ��������ԭʼ��и�����ֵ��ƽ��ֵӋ��õ�����̎���Y(ji��)����D5��ʾ��“����”��“���ˣ�’���ϲ���ͬһ�“����”�“ͬ��”��“�T��”���ϲ���ͬһ�“ͬ��”���ӱ�ֵ�����ԭʼ��Иӱ�ֵ��ƽ��ֵ��
2.2�㷨�����_����C
�����е����H�P(gu��n)ϵ�A�yֻᘌ���ͨ(li��n)���ѽ��������P(gu��n)ϵ���Ǿ��w���ںηN�P(gu��n)ϵ���δ֪����r�����A�y���@��һ�N����}�����A�y�^���У��鱣�C�A�y�㷨����Ч�ԣ����Č�����K�۽�����C�u��������K�۽�����C������ʼ�ӱ��ָ��K�����ϣ�����һ���Ϊ����Әӱ�������Cģ�͵Ĕ�(sh��)��(j��)������K-1���ӱ�����Ӗ�������齻����C���؏�K�Σ�ÿ��ᘌ�һ���Әӱ���Cһ�Σ�����ƽ��K�εĽY(ji��)�����鱾�㷨���A�y�ʴ_�ʡ�
���IJ��ö�N�u�r���������A�y�㷨�M���u�r���������_�ʡ��ٻ��ʡ���F-Measure�������Զ�Ԫ����}�Ļ�����ꇁ��f�����ώׂ��u�rָ�˵ĺ��x��
���O(sh��)���H�P(gu��n)ϵֻ�ЃɷN��“����”��“�H��’��
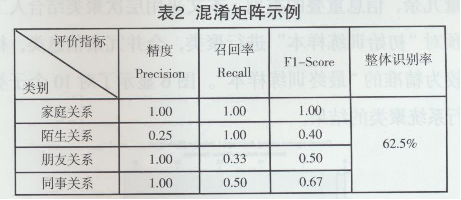
�ı�2��֪���ڌ��H���A�y�У��κ�һ����A�y�����ЃɷN�Y(ji��)����1�����_���A�y��2���e�`���A�y���Ķ��γ����V��������( True Positive)����ؓ��(True Negative)����ؓ��( False Negative)��������(False Positive)����r��ͬ�r����������( True Positive)����ؓ��(True Negative)�ı����^�ߕr������ζ��ģ�����w���A�y���_�ʾߣ��ڻ�������б��F(xi��n)�锵(sh��)ֵ�����ھ�ꇵ������Ǿ��ϡ����_�ʡ����_�ʡ��ٻ��ʺ�AUC��Ӌ�㷽��������ʾ��
1)���_�ʣ���ӳ������A�y���_�ʣ������w�R�e�ʡ�
![]()
2)���_�ʣ���ӛ�����Ԫ�M���H�������ռ�İٷֱȣ��������б�ʾ������“�����P(gu��n)ϵ”���A�y�ı�������

4) һ����Y(ji��)���ĺÉĵ������������Ƿ�ͬ�r���и������Ժ��خ��ԣ���AUCǡ�ýY(ji��)���˃��ߵ����ԡ�AUC��ROC�����̓������S���ɵą^(q��)����e��ԓ��eԽ��t��ʾ�A�y�ʴ_��Խ�ߡ�AUC�Ļ���ֵ��0.5�����S�C�y��
3��������
3.1���ڌӴξ��Ӗ���ӱ��Ę�(g��u)��
ģ�M��ͨ(li��n)��(sh��)��(j��)�������������ķ��~����Ȼ�Z��̎���ȼ��g(sh��)��ȡͨ(li��n)�еĺ��ѷֽM��Ϣ��Ȼ���ԃɃ�ͨ(li��n)���ў�Ӌ�㌦�քeӋ��ɂ����ѵĹ�ͬ���є�(sh��)��ռ���ѿ���(sh��)�ı���CFR��ƽ��ͨ(li��n)�Δ�(sh��)AR��ƽ��ͨ(li��n)�r�LATR��ƽ����Ϣ�����Δ�(sh��)AM,�õ�‘��ʼӖ���ӱ�”��4�����������
���ڲ�ͬ��ͨ(li��n)���ߣ���ֽM���R������ͬ�������Ñ����Զ��x�ֽM��Ϣ���@�،����³��F(xi��n)�����ķֽM�������F(xi��n)�����ķ��e���磺“ͬ�W”��“ͬ��”��“����”��“�T��”��“ͬ��”�ȡ��@Ȼ��“�T��”��“ͬ��”�@�ɂ������һ���̶����ǿ��Ժϲ�̎���ģ��Ķ�������ʹ�÷���㷨�r�����F(xi��n)�������ࡢ��Ϣ�دB��e�����IJ��ÌӴξ�Y(ji��)���˹����A��“��ʼӖ���ӱ�”�M�о���ϲ�������Ϣ��õ��^�龫�ʵ�“��KӖ���ӱ�”���D6�@ʾ�ˌ�10������M��ϵ�y(t��ng)��ĽY(ji��)����
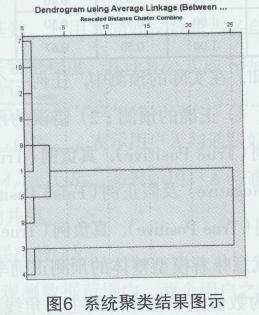
�ɈD6��֪�������3�r�����System Group��Friend����ͬ�¡�����(li��n)ϵ��һ̖���ڼ�2̖��T�������ˡ��T����Favorite_8656150��6������ϲ���l�İ���ˡ�agehaС��ħ���ϲ���1�����(li��n)ϵ��TIARA������(li��n)ϵ�˼�ͥ���ϲ���1�
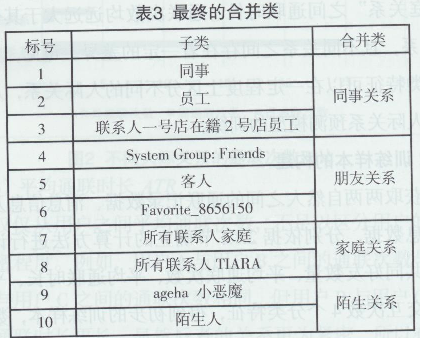
��ĽY(ji��)���^��������������ֵ�^�����������ϲ���һ���������(li��n)ϵ��TIARA������(li��n)ϵ�˼�ͥ��2����ͨ�����^���l���������İ���ˡ�agehaС��ħ��2����ͨ�l�^��2������b�ڱ��ĵ��о������Č�ϵ�y(t��ng)��ĽY(ji��)���Mһ���M���{(di��o)�����ϲ���4�����Y(ji��)�����£�
3.2����SVM�����H�P(gu��n)ϵ�A�yģ�͘�(g��u)��
3.2.1���H�P(gu��n)ϵ�A�yģ��Ӗ��
����(j��)3.1��(ji��)ϵ�y(t��ng)��ĽY(ji��)������Ӗ���ӱ��M���{(di��o)�����ϲ�������ϲ������Ӗ���ӱ����̖���xȡ70%�Ęӱ�����Ӗ���ӱ�������֧�������CSVM�M��ģ��Ӗ����ʣ��30%�Ęӱ�����ģ�͵����_�ʙz���H�a(ch��n)�P(gu��n)ϵ�A�yģ�͵�Ӗ���^����D7��ʾ��

![]()
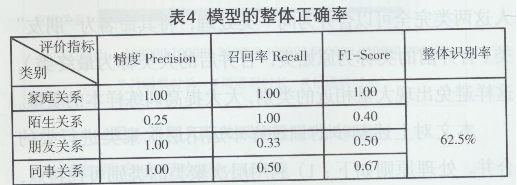
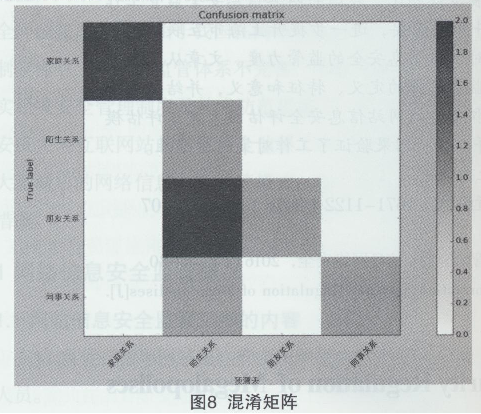
���4��ʾ�����ڱ��ĬF(xi��n)�е�Ӗ����(sh��)��(j��)�����û��ڏ�����˺���(sh��)��֧�������C�M�����H�P(gu��n)���A�yģ�͵��A�y���ڬF(xi��n)�Д�(sh��)��(j��)�У������F(xi��n)4�����H�P(gu��n)ϵ��ͣ��քe��“��ͥ�P(gu��n)ϵ”��“İ���P(gu��n)ϵ”��“�����P(gu��n)ϵ”��“ͬ���P(gu��n)ϵ”��ģ�͵����w�R�e�ʞ�62.5%��ͬ�r��“��ͥ�P(gu��n)ϵ”��“ͬ���P(gu��n)ϵ”���A�y�^�龫�ʣ�������“��ͥ�P(gu��n)ϵ”�侫�Ȟ�100%����“İ���P(gu��n)ϵ”��“�����P(gu��n)ϵ”���A�y�ʴ_���^�ͣ�“İ���P(gu��n)ϵ”�ľ��ȃH��25%����D8��ʾ����������@ʾ�˱�����������H�P(gu��n)ϵ�A�yģ�������r��
4�Y(ji��)���Z
������ͨ(li��n)��(sh��)��(j��)���о��������Ȼ����]���̓�M������Ϣ������ͬһ������Ñ��w�M���R�e����̎������β������ķ��~����Ȼ�Z��̎���ȷ�����ȡͨ(li��n)��(sh��)��(j��)�еķֽM��Ϣ���������������H�P(gu��n)ϵ�W(w��ng)�j(lu��)�����O(sh��)Ӌ��ͬ���є�(sh��)��ռ���ѿ���(sh��)�ı���CFR��ƽ��ͨ(li��n)�Δ�(sh��)AR��4�����������������ϵ�y(t��ng)�����Ӗ����(sh��)��(j��)�M�о���Y(ji��)���˹����A�ϴ_����K�Ӗ���ӱ����Ķ�����ͨ(li��n)�ֽM��Ϣ�����࣬�������ij��F(xi��n)��Ȼ�������Ϸ����Ļ��A(ch��)�ϣ������m��С�ӱ���֧�������C�㷨���M��ģ��Ӗ�����õ��m��ͨ(li��n)��(sh��)��(j��)���H�P(gu��n)ϵ�A�y�ķ��ģ�͡����Y(ji��)�����������㷨�܉��R�e���W(w��ng)�j(lu��)�е�ȫ������“��ͥ�P(gu��n)ϵ”���������w�ϱ��C�����^�ߵĜʴ_�ʣ�����һ���đ�(y��ng)�Ãrֵ��
��һƪ:����̓�M�x���ĺ�늜yԇϵ�y(t��ng)�о�(ͨӍ)
��һƪ:����һ�N�șz�y�A̎�������l�ʽ�׃���}�_���_���W�q���Ʒ�����ͨӍ��
�ИI(y��)�YӍ���c������
չ����Ϣ���c������
- 1 2019�Ї����B�T�����H���R�I(y��)չ�[��
- 2 2019�Ͼ��V��չ����չ����ԃ������18952050067��
- 3 2019�Ї����B�T�����H���R�I(y��)���[��
- 4 2019��ϷʏV��չ����ԃ�Ԓ��18952050067������
- 5 2019�������H�Ƶ���Ʒ���O(sh��)�䲩�[��
- 6 2019�Ϻ����H��ů�����{(di��o)��ü��g(sh��)�O(sh��)��չ�[��
- 7 2019�꣨��ʮ��ã��Ϻ����Hˮ̎�����WƷչ�[��
- 8 2019��20�����·��Hģ�߹��I(y��)չ�[��